A Modelagem Dimensional é um dos fundamentos mais importantes do BI e da análise de dados. Se você trabalha com Power BI, Data Warehouse ou Engenharia de Dados, provavelmente já ouviu termos como Star Schema, tabela fato, tabela dimensão ou Snowflake. Mas o que isso significa na prática? Por que esses conceitos importam? E como aplicá-los corretamente?
Neste artigo vou explicar tudo de forma clara, com exemplos práticos e direto ao ponto.
O que é Modelagem Dimensional?
Modelagem dimensional é uma técnica de design de banco de dados desenvolvida especificamente para suportar consultas analíticas de forma eficiente. Foi popularizada por Ralph Kimball nos anos 1990 e até hoje é a base da maioria dos Data Warehouses corporativos.
A ideia central é organizar os dados em dois tipos de tabela:
- Tabelas fato (fact tables): armazenam os eventos mensuráveis do negócio — vendas, transações, pedidos, visitas. Contêm métricas numéricas e chaves estrangeiras para as dimensões.
- Tabelas dimensão (dimension tables): armazenam o contexto dos eventos — quem, o quê, onde, quando, como. Exemplos: clientes, produtos, datas, regiões, canais de venda.
A combinação dessas duas estruturas permite responder perguntas de negócio de forma rápida e intuitiva: qual foi o faturamento por produto por região no último trimestre? Quais clientes compraram mais de três vezes nos últimos 30 dias?
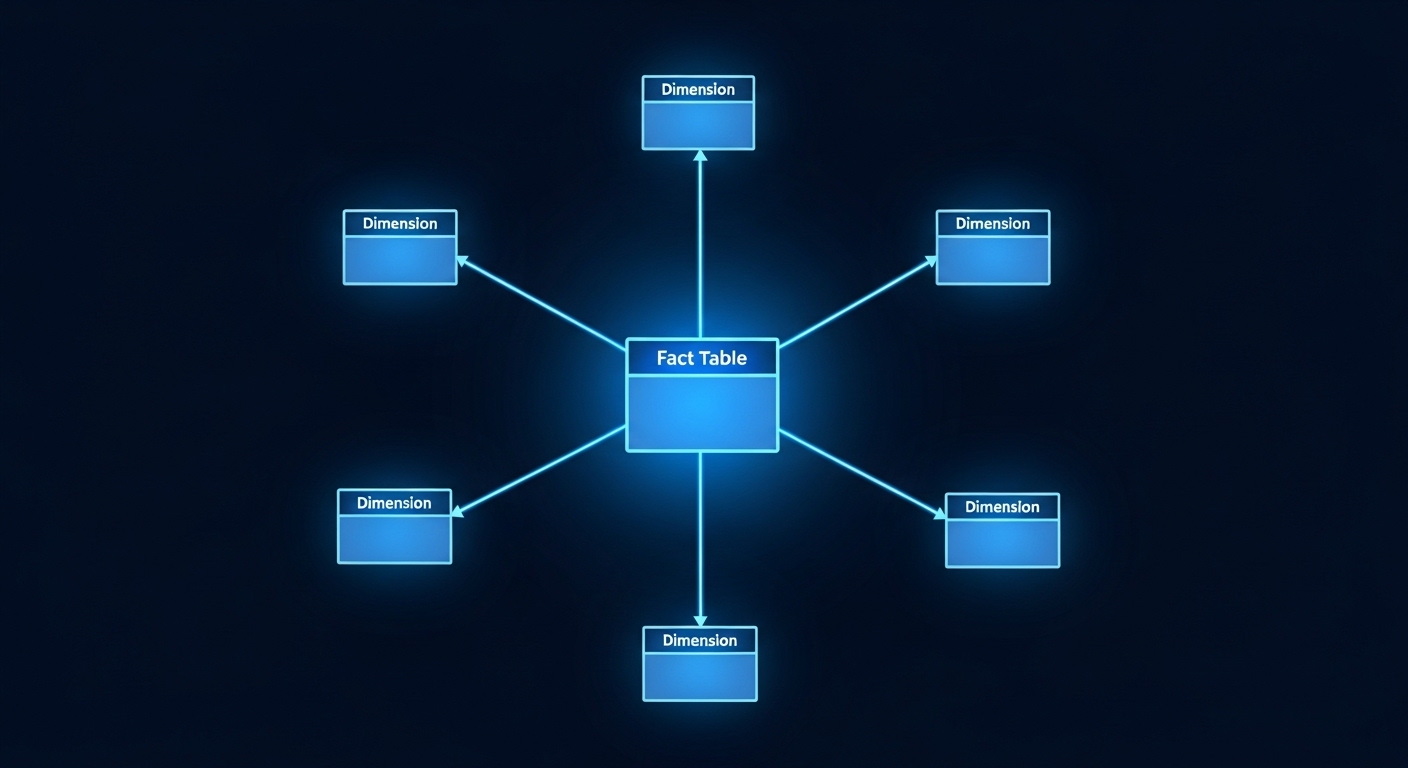
Esquema Estrela — o modelo mais usado
O esquema estrela (ou star schema) é a forma mais comum de modelagem dimensional. O nome vem da aparência do diagrama: a tabela fato no centro, conectada diretamente às tabelas dimensão ao redor — formando uma estrela.
Exemplo prático: modelo de vendas
Imagine uma empresa de varejo. O modelo estrela para análise de vendas seria:
Tabela fato: Vendas
- id_venda (chave primária)
- id_produto (chave estrangeira → dim_produto)
- id_cliente (chave estrangeira → dim_cliente)
- id_data (chave estrangeira → dim_data)
- id_loja (chave estrangeira → dim_loja)
- quantidade
- valor_total
- desconto
Tabelas dimensão:
- dim_produto: id_produto, nome, categoria, subcategoria, marca, fornecedor
- dim_cliente: id_cliente, nome, cidade, estado, segmento, data_cadastro
- dim_data: id_data, data, dia, mês, trimestre, ano, dia_semana, é_feriado
- dim_loja: id_loja, nome, cidade, estado, região, gerente
Com esse modelo, uma consulta como ‘faturamento por categoria de produto por trimestre na região Sul’ é direta, eficiente e intuitiva.
| Por que a dim_data é tão importante? A tabela de data (também chamada de calendário) é a dimensão mais usada em qualquer modelo de BI. Ela permite análises por dia, semana, mês, trimestre, ano, dia da semana, feriados e períodos fiscais. Nunca use a data diretamente da tabela fato — sempre crie uma dim_data dedicada. |
Esquema Floco de Neve — quando normalizar faz sentido
O esquema floco de neve (ou snowflake schema) é uma variação do esquema estrela onde as tabelas dimensão são normalizadas — ou seja, subdivididas em tabelas menores para eliminar redundâncias.
No exemplo anterior, a dim_produto tinha os campos categoria e subcategoria diretamente na tabela. No floco de neve, esses campos seriam movidos para tabelas separadas:
- dim_produto → id_categoria (FK) + id_subcategoria (FK)
- dim_categoria → id_categoria, nome_categoria
- dim_subcategoria → id_subcategoria, nome_subcategoria, id_categoria (FK)
O resultado parece um floco de neve no diagrama — dimensões com ramificações que se conectam a subdimensões.
Quando usar floco de neve?
Na prática, o esquema floco de neve é usado quando:
- O volume de dados nas dimensões é muito grande e a redundância gera problemas de armazenamento
- Há necessidade de manter integridade referencial rigorosa nos dados
- O ambiente é um Data Warehouse relacional tradicional com restrições de espaço
Importante: para Power BI, o esquema estrela quase sempre é a escolha certa. O Power BI é otimizado para esse modelo — o motor VertiPaq (que comprime e armazena os dados em memória) funciona de forma muito mais eficiente com dimensões desnormalizadas.
Estrela vs Floco de Neve — comparativo
| Característica | Esquema Estrela | Esquema Floco de Neve |
| Estrutura | Tabela fato + dimensões diretas | Tabela fato + dimensões normalizadas |
| Normalização | Desnormalizado (redundância permitida) | Normalizado (sem redundância) |
| Performance de consulta | Alta — menos JOINs | Menor — mais JOINs necessários |
| Complexidade de manutenção | Mais simples | Mais complexo |
| Uso de espaço | Maior (dados repetidos) | Menor (dados normalizados) |
| Ideal para | Power BI, relatórios, BI corporativo | Data Warehouses com dados muito grandes |
Medidas e métricas — o coração do modelo
As tabelas fato armazenam os números que o negócio precisa analisar. Mas existem dois tipos de métricas que é importante distinguir:
Métricas aditivas: podem ser somadas em qualquer dimensão. Exemplo: quantidade vendida, valor de venda. Você pode somar por produto, por cliente, por região — o resultado sempre faz sentido.
Métricas semi-aditivas: podem ser somadas em algumas dimensões, mas não em todas. Exemplo: saldo bancário. Você pode somar por cliente (saldo total dos clientes), mas não por data (saldo de janeiro + saldo de fevereiro não faz sentido — você quer o saldo no final do período, não a soma).
Métricas não-aditivas: não podem ser somadas. Exemplo: percentual, taxa de conversão, margem. Para esses casos, você precisa calculá-los a partir de métricas aditivas — nunca armazene percentuais direto na tabela fato.
| Dica prática para Power BI Evite criar medidas calculadas em colunas da tabela fato quando possível. Prefira criar medidas DAX explícitas. Isso melhora a performance, a manutenibilidade e o reaproveitamento do modelo semântico. |
Granularidade — a decisão mais importante do modelo
A granularidade define o nível de detalhe de cada linha na tabela fato. É a decisão mais importante que você toma ao projetar um modelo dimensional — e impacta diretamente o que você consegue ou não analisar.
Exemplos de granularidade em um modelo de vendas:
- Granularidade por item de pedido: cada linha representa um produto em uma venda. Alta granularidade, máximo detalhe.
- Granularidade por pedido: cada linha representa uma venda completa. Você perde a análise por produto individual.
- Granularidade diária: cada linha representa o total de vendas de um dia. Você perde a análise por transação.
A regra geral é: sempre defina a granularidade no nível mais detalhado que o negócio precisa analisar. Você pode sempre agregar (subir o nível), mas nunca pode desagregar (baixar o nível) se os dados não foram capturados nessa granularidade.
Aplicando na prática: Power BI e Data Warehouse
No Power BI
O Power BI foi construído para trabalhar com modelagem dimensional. Ao importar dados para o Power BI Desktop, você está criando um modelo semântico — e esse modelo deve seguir os princípios do esquema estrela.
Boas práticas para modelagem no Power BI:
- Separe claramente tabelas fato e dimensão — nunca misture métricas e atributos descritivos na mesma tabela.
- Crie sempre uma dim_data dedicada — nunca use a data diretamente da tabela fato.
- Use relacionamentos de um-para-muitos (1:N) da dimensão para a fato.
- Evite relacionamentos bidirecionais — use-os apenas quando necessário e com cautela.
- Desnormalize as dimensões — prefira o esquema estrela ao floco de neve.
- Nomeie colunas e medidas de forma clara e consistente — o modelo semântico é consumido por outras pessoas.
No Data Warehouse
Em um Data Warehouse relacional (SQL Server, Synapse, Redshift, BigQuery), a modelagem dimensional define a camada de apresentação — a camada que os usuários finais e as ferramentas de BI consomem.
A arquitetura típica tem três camadas:
- Staging (área de staging): dados brutos carregados das fontes, sem transformação
- ODS (Operational Data Store): dados integrados e limpos, ainda em formato relacional normalizado
- DW (Data Warehouse): dados modelados dimensionalmente, otimizados para consulta analítica
A camada DW é onde o esquema estrela vive — e é o que o Power BI, Tableau ou qualquer outra ferramenta de BI consome.
Erros comuns na modelagem dimensional
Ao longo dos anos trabalhando com modelos de dados em empresas de diferentes setores, esses são os erros que vejo com mais frequência:
- Misturar fato e dimensão na mesma tabela: criar uma tabela única com métricas e atributos descritivos. Isso gera redundância, dificulta manutenção e prejudica performance.
- Não criar uma dim_data: usar a data diretamente da tabela fato impossibilita análises por dia da semana, mês, trimestre e feriados sem lógica extra.
- Granularidade incorreta: definir granularidade muito alta (agregada demais) e depois perceber que o negócio precisa de mais detalhe.
- Métricas calculadas como colunas: armazenar percentuais e taxas diretamente na tabela fato em vez de calculá-los dinamicamente.
- Chaves naturais como chaves primárias: usar o código do cliente do sistema de origem como chave primária da dimensão. O correto é criar uma surrogate key (chave substituta) numérica e sequencial.
Conclusão
Modelagem dimensional é a base de qualquer projeto de BI bem estruturado. O esquema estrela é simples, intuitivo e otimizado para consultas analíticas — e é por isso que continua sendo o padrão da indústria após décadas.
Se você trabalha com Power BI, dominar modelagem dimensional vai fazer uma diferença enorme na performance dos seus modelos, na facilidade de manutenção e na qualidade das análises que você consegue entregar.
E se você está construindo um Data Warehouse, a camada dimensional é o que vai determinar se as pessoas vão confiar nos dados — ou se vão continuar fazendo análises em planilhas porque o DW é “complicado demais”.
Escrito por Fabio Leandro Ribeiro — Customer Engineer Data/AI na Microsoft. Criador do canal Opus Data no YouTube.